What We've Learned from Building AI Copilots

By Hasna Najmi / Senior AI Solutions Architect
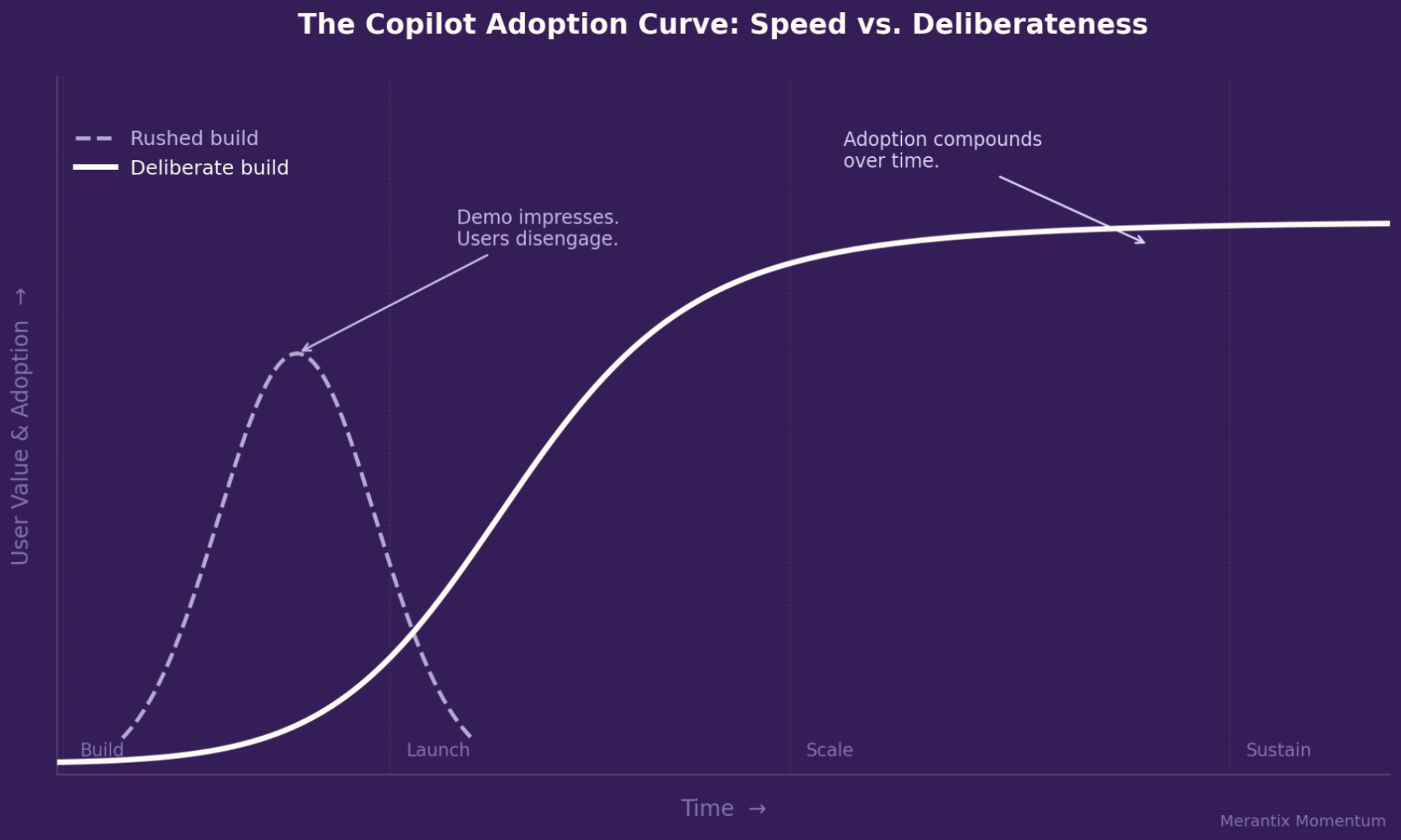
The gap between a co-pilot that impresses in a demo and one that actually changes the way people work is wider than many teams expect.
Every week, another company announces that it has developed an AI copilot. A compelling demo, positive internal buzz, and then, all too often, quiet underutilization six months later.
Over the past three years , we have implemented Copilot systems in some of the most demanding environments: large public-sector organizations, specialized legal settings, and enterprise workflows with thousands of daily users. We have seen what works. And we have seen what fails. What stands out is that the reasons for failure are strikingly similar.
Here’s what every team should know before building a co-pilot.
The retrieval phase is where co-pilots most often fail
There’s a type of co-pilot that everyone is familiar with: he sounds convincing, answers fluently, and is wrong just often enough that you stop trusting him. The cause is almost always the retrieval.
Most enterprise copilots are document-based. They draw context from internal knowledge bases, policies, manuals, or databases before generating responses. The quality of the content they find determines the upper limit of the quality of each response.
Generic retrieval pipelines designed for general-purpose text often do not perform reliably in specialized domains.
Legal language works differently from everyday language. The same goes for clinical terminology. Or the abbreviations and logic used in technical specifications. If the retrieval system does not take into account how subject matter experts actually phrase their questions, it will almost certainly retrieve the wrong results.
This is one of the most effective strategies early on in the process of building a co-pilot. And at the same time, it’s one of the most frequently underestimated.
Your power users aren't your only users
It’s tempting to build a co-pilot for the users who are most interested in it, the early adopters who are familiar with AI, write creative prompts, and push the system to its limits.
They provide valuable feedback. But they do not represent the organization.
Those who would benefit most from a good co-pilot are often the ones who feel least confident using it. If the only way to get started is by entering blank text with no guidance, these very users will immediately give up, and usage will never recover.
Copilots who make their mark across the organization offer several entry points:
An open-ended experience for experienced users. And structured, guided options for everyone else.
It may seem like a minor UX decision, but it has a huge impact on adoption.
If you can't measure it, you can't improve it
A scenario that happens all too often: A team builds a copilot, tests it internally, rolls it out, and then has no systematic way of evaluating whether it actually works.
Six months later, someone asks, “Is this thing actually any good?”
And no one can answer them.
Evaluation must be defined before construction begins, not after. This means:
- Clearly define what “good” means in this specific use case
- Collect real user data for testing
- Integrate monitoring to detect changes in quality
Synthetic benchmarks have their place. But they don't reveal the problems that real users encounter.
People ask questions in unexpected ways. They test the limits. They use systems in ways other than those intended. That is exactly what needs to be made visible.
Governance is not a legal issue. It is an architectural issue.
Especially in regulated industries, governance is often left until the very end: a legal review, a few guidelines, and a final approval.
That's not how it works.
Data protection, traceability, and regulatory requirements, including the EU AI Act, must be built into the system architecture from the very beginning. Retrofitting these features is time-consuming, expensive, and rarely comprehensive.
And even more importantly:
A copilot who confidently gives the wrong answers in a critical situation doesn’t just create a problem in the moment, it destroys trust.
And once trust is lost, it is difficult to rebuild.
The most important metric is time
Retrieval scores, benchmarks, evaluation metrics, they are essential for development.
But they don't decide whether a copilot will be used in the long term.
The key point is:
Will users get their time back?
- Will a 20-minute task turn into a 5-minute task?
- Do unpleasant tasks become easier?
That is what drives genuine adoption, internal advocates, and sustainable investment.
The most successful co-pilots aren't the ones that have been optimized based on metrics.
Rather, those whose teams have a deep understanding of real-world work processes, and have designed their solutions by working backward from there.
Speed is important in AI development. But it doesn't determine whether a copilot will be successful in the long run.
Successful systems are created deliberately:
with a focus on retrieval, evaluation, user experience, and governance, from the very beginning.
We learned these lessons the hard way, in real production systems, on a large scale.
If you're building a co-pilot and would like to discuss architecture, implementation, or scaling, please feel free to reach out to us.
Merantix Momentum is an Applied AI company that helps organizations develop and operate production-ready AI systems.
Subscribe to the Merantix Momentum Newsletter now.
More articles
.png)
.png)
.png)
.png)
What We've Learned from Building AI Copilots
By Hasna Najmi / Senior AI Solutions Architect
The gap between a co-pilot that impresses in a demo and one that actually changes the way people work is wider than many teams expect.
Every week, another company announces that it has developed an AI copilot. A compelling demo, positive internal buzz, and then, all too often, quiet underutilization six months later.
Over the past three years , we have implemented Copilot systems in some of the most demanding environments: large public-sector organizations, specialized legal settings, and enterprise workflows with thousands of daily users. We have seen what works. And we have seen what fails. What stands out is that the reasons for failure are strikingly similar.
Here’s what every team should know before building a co-pilot.
The retrieval phase is where co-pilots most often fail
There’s a type of co-pilot that everyone is familiar with: he sounds convincing, answers fluently, and is wrong just often enough that you stop trusting him. The cause is almost always the retrieval.
Most enterprise copilots are document-based. They draw context from internal knowledge bases, policies, manuals, or databases before generating responses. The quality of the content they find determines the upper limit of the quality of each response.
Generic retrieval pipelines designed for general-purpose text often do not perform reliably in specialized domains.
Legal language works differently from everyday language. The same goes for clinical terminology. Or the abbreviations and logic used in technical specifications. If the retrieval system does not take into account how subject matter experts actually phrase their questions, it will almost certainly retrieve the wrong results.
This is one of the most effective strategies early on in the process of building a co-pilot. And at the same time, it’s one of the most frequently underestimated.
Your power users aren't your only users
It’s tempting to build a co-pilot for the users who are most interested in it, the early adopters who are familiar with AI, write creative prompts, and push the system to its limits.
They provide valuable feedback. But they do not represent the organization.
Those who would benefit most from a good co-pilot are often the ones who feel least confident using it. If the only way to get started is by entering blank text with no guidance, these very users will immediately give up, and usage will never recover.
Copilots who make their mark across the organization offer several entry points:
An open-ended experience for experienced users. And structured, guided options for everyone else.
It may seem like a minor UX decision, but it has a huge impact on adoption.
If you can't measure it, you can't improve it
A scenario that happens all too often: A team builds a copilot, tests it internally, rolls it out, and then has no systematic way of evaluating whether it actually works.
Six months later, someone asks, “Is this thing actually any good?”
And no one can answer them.
Evaluation must be defined before construction begins, not after. This means:
- Clearly define what “good” means in this specific use case
- Collect real user data for testing
- Integrate monitoring to detect changes in quality
Synthetic benchmarks have their place. But they don't reveal the problems that real users encounter.
People ask questions in unexpected ways. They test the limits. They use systems in ways other than those intended. That is exactly what needs to be made visible.
Governance is not a legal issue. It is an architectural issue.
Especially in regulated industries, governance is often left until the very end: a legal review, a few guidelines, and a final approval.
That's not how it works.
Data protection, traceability, and regulatory requirements, including the EU AI Act, must be built into the system architecture from the very beginning. Retrofitting these features is time-consuming, expensive, and rarely comprehensive.
And even more importantly:
A copilot who confidently gives the wrong answers in a critical situation doesn’t just create a problem in the moment, it destroys trust.
And once trust is lost, it is difficult to rebuild.
The most important metric is time
Retrieval scores, benchmarks, evaluation metrics, they are essential for development.
But they don't decide whether a copilot will be used in the long term.
The key point is:
Will users get their time back?
- Will a 20-minute task turn into a 5-minute task?
- Do unpleasant tasks become easier?
That is what drives genuine adoption, internal advocates, and sustainable investment.
The most successful co-pilots aren't the ones that have been optimized based on metrics.
Rather, those whose teams have a deep understanding of real-world work processes, and have designed their solutions by working backward from there.
Speed is important in AI development. But it doesn't determine whether a copilot will be successful in the long run.
Successful systems are created deliberately:
with a focus on retrieval, evaluation, user experience, and governance, from the very beginning.
We learned these lessons the hard way, in real production systems, on a large scale.
If you're building a co-pilot and would like to discuss architecture, implementation, or scaling, please feel free to reach out to us.
Merantix Momentum is an Applied AI company that helps organizations develop and operate production-ready AI systems.



.png)
.png)